
Development of Fast and Automatic Service recovery and Transition software in Hybrid Cloud Environment
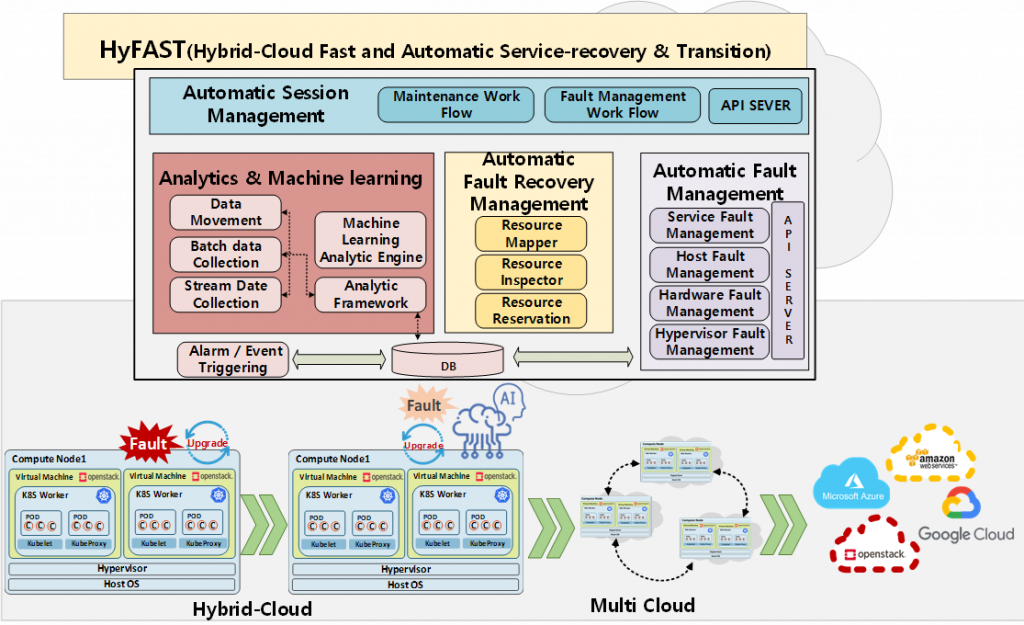
The StarLab project aims to secure university-oriented global source technologies by selecting and supporting excellent laboratories that have accumulated basic and source technologies in each SW field and can conduct practical research. The lab has been selected for the cloud field and will perform “Development of Fast and Automatic Service recovery and Transition software in Hybrid Cloud Environment”. This project was started in 2020 and will be ended in 2027.
For this project, the lab develops HyFAST System on its own. The project is being carried out in three stages, and various management and maintenance features are currently being developed in a hybrid-cloud environment (OpenStack and Kubernetes) where VM and container infrastructure are mixed in the first stage until 2023.
The project is progressed into 3 stages.
- Stage1 – Development of HyFAST in hybrid cloud environment
- Fast and automatic service recovery and transition software based on multilayer monitoring
- Automation workflow and integrated orchestration software
- Situational data (e.g. Event, Log, Multilayered state) management
- ML-based analysis and prediction features
- Stage2 – Development of HyFAST in multi-cloud and heterogeneous cloud environments
- Extending orchestration features to support heterogeneous cloud environments
- Extending orchestration features to support multi-site environments such as distributed edge clouds
- Stage3 – Demonstration and optimization of HyFAST
- Demonstration of HyFAST that applied in private cloud and edge cloud
- Optimization of automation features
Research and Development Achievements
Offline Events (KubeCon, IETF, …)





KPI (Stage 1)
| Evaluation Item | Target Value | Description |
|---|---|---|
| Failure Detection Time | ≤ 0.9 sec | The time taken from the occurrence of a failure caused by various factors until it is detected by the developed software |
| Service Recovery Time | ≤ 6 sec | The time from the detection of a system or service failure to its complete recovery |
| Service Availability Level | Level 1 | The service availability level of the cloud infrastructure |
| Evaluation Item (Key Performance Indicator) | Unit | R&D Result / Target Value | Achievement Level |
|---|---|---|---|
| Failure Detection Time | sec | 0.8/0.9 | 100 |
| Service Recovery Time | sec | 4.3/6 | 100 |
| Service Availability Level | Level | 1/1 | 100 |
Key Activities
- Design and Development of an Automated Hybrid Cloud Provisioning System
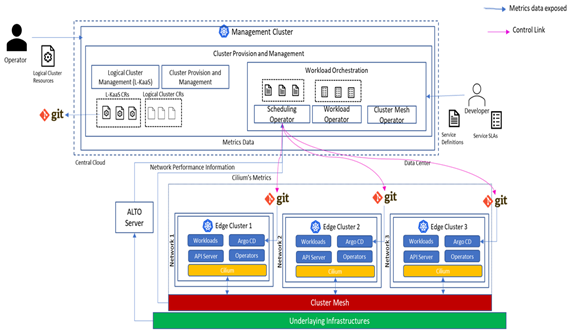
- Developed a remote automated provisioning system for Logical Kubernetes Clusters across multi-cloud environments (including distributed edge) based on Kubernetes design principles.
- Each Cluster resource contains configuration details such as infrastructure provider, network settings, middleware, and required software, and the system executes the provisioning process to reach the desired state accordingly.
- Development of an ML-Based Multi-Context Data Collection System and Root Cause Analysis (RCA) Framework for Failure Detection
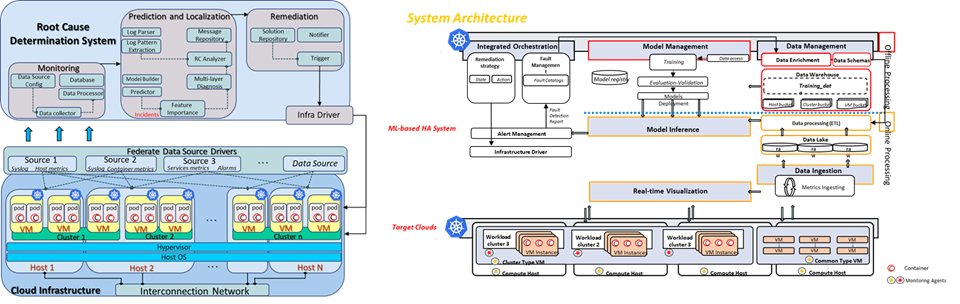
- Developed real-time monitoring and machine learning-based prediction capabilities for system-wide data and specific infrastructure layers and characteristics
- Implemented multi-anomaly prediction and root cause analysis (RCA) to identify primary failure sources upon detection
- Modularized the entire system architecture into components including Orchestration, Model Management, Model Inference, Data Management, Data Ingestion, and Visualization
- Design and Implementation of Stateful Workload Migration Mechanism
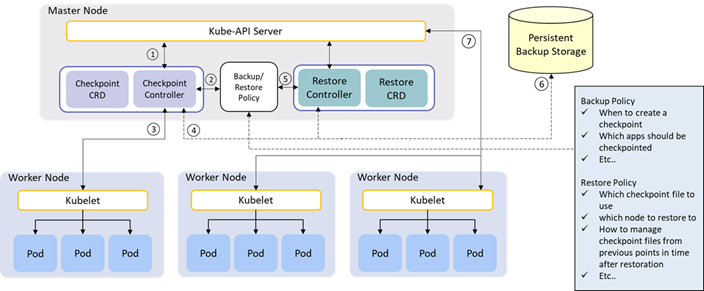
with Velero Integration and Extension
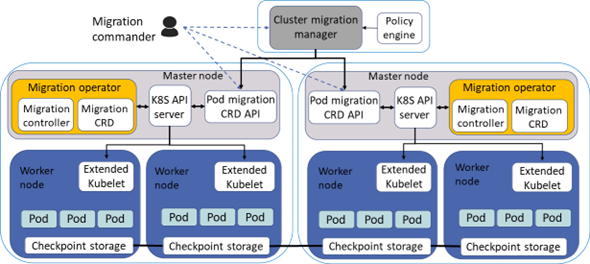
with Pod Migration Controller
- Designed the system to enable seamless Pod migration without service disruption by retrieving the state of the running workload upon receiving a Pod Migration request triggered by RCA.
- Developed custom Pod Migration resources and a dedicated controller to manage the migration process.
- Extended the existing research by integrating with CRIU and Velero, enabling the migration of workloads from Day2 clusters to Day1 clusters.
- Development of Machine Learning-Based Autoscaling for QoE Optimization
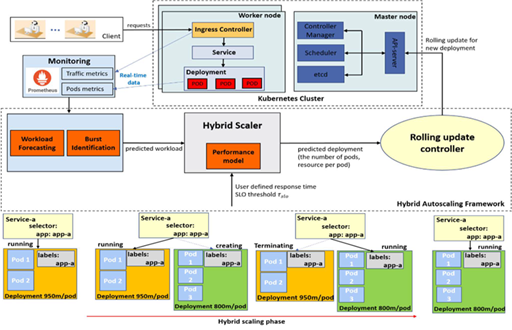
- Enhanced the existing Kubernetes autoscaling components—Horizontal Pod Autoscaler (HPA) and Vertical Pod Autoscaler (VPA)—with machine learning techniques to ensure Quality of Experience (QoE).
- Extended the research to the serverless open-source project Knative, achieving improved resource efficiency and QoE compared to the project’s default high-performance options.
Link to project-related software
- Velero based Stateful-Backup
- Velero based Stateful-Backup Operator.
- Fault-Root-Cause-Analysis-System
- A project to develop a system that automatically predicts and recovers from cloud failures.
- L-KaaS
- Kubernetes based Infra Bootstrap System with Cloud-Native way
- podmigration-operator
- CRIU based Stateful Backup Operator
- workflow-based-auto-recovery
- Workflow-based Monitoring and Fault Detection System