
Cloud Continuum for Enabling Large Scale AI Services
Main institute: Kyunghee Univ.
Ministry: MSIT(Ministry of Science and ICT)
Organization: IITP (Institute for Information & communications Technology Promotion)
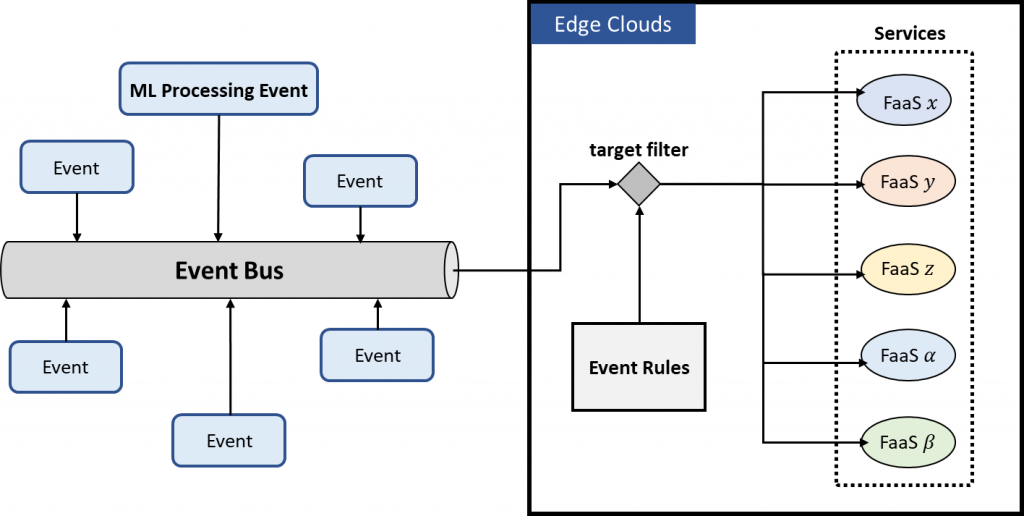
FaaS Architecture in Edge Cloud Environments
Federated Event-Driven Serverless Computing Technology in Edge Cloud Environments
- Serverless Computing Serving in Edge Cloud Environments
- Event Processing for Federated Learning Models via Serverless Computing
- Integration of Event-Service Architecture for Federated Learning Processing
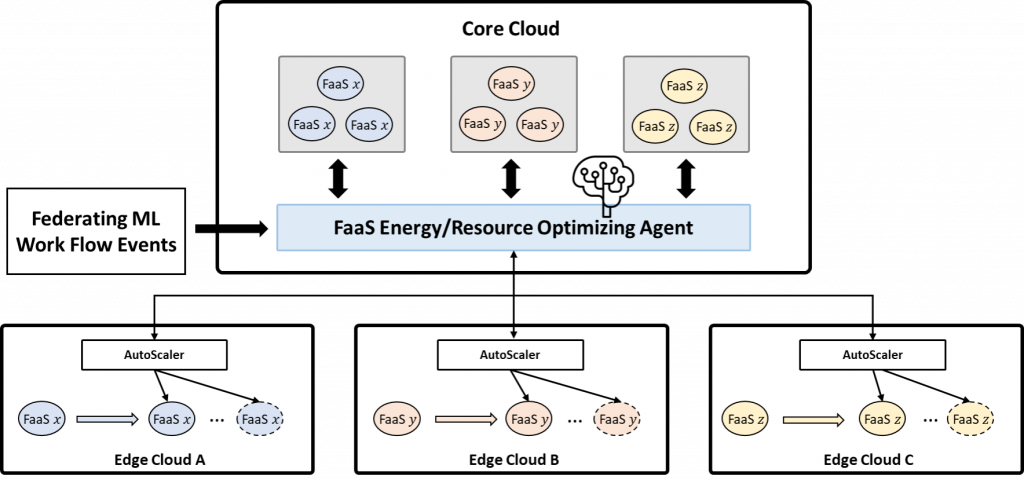
Architecture of Serverless Computing in a Cloud-Edge-Device Environment
Serverless Computing Technology in a Cloud-Edge-Device Environment
- Integration Technology of Event-Service Architecture for Federated Learning
- Resource Optimization and Auto-Scaling Technology in a Federated Cloud-Edge-Device Serverless Computing Environment
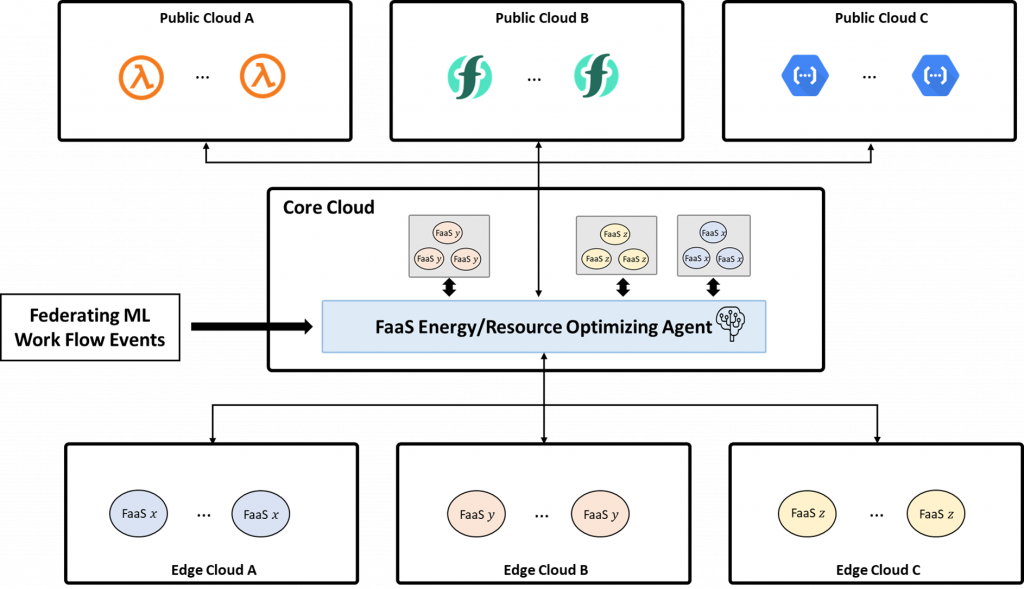
Architecture for Heterogeneous and Multi-Platform Serverless Computing
Federated Multi-Cloud Serverless Computing Technology
- Development and Integration of a Multi-Cloud FaaS Framework
- Integrated Application of Various Federated Learning Service Models
Research and Development Achievements
Key Activities
- Design of Event Bus-based Serverless Computing for Distributed Edge Cloud Environments
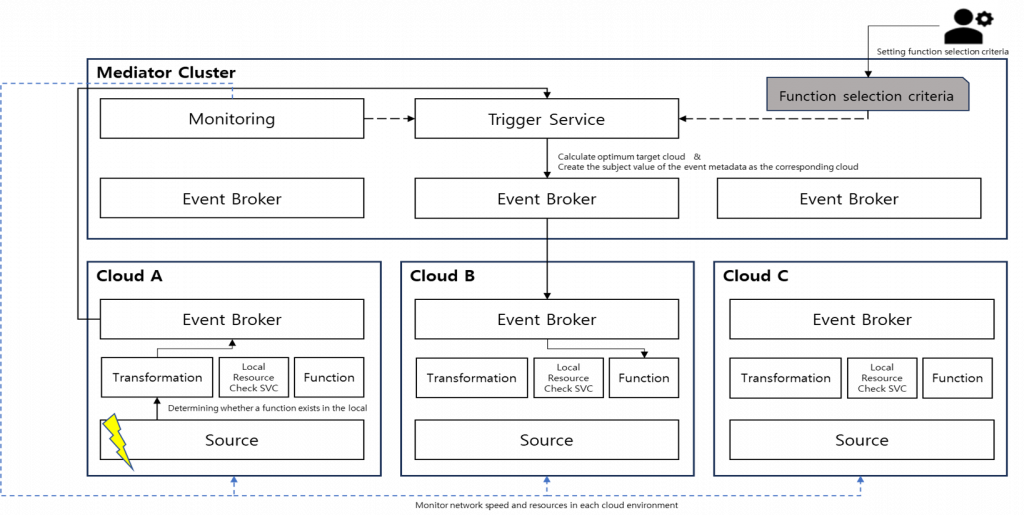
Architecture of an Event-based FaaS Selection System for Distributed Cloud Environments
- An architecture that, when an event occurs and the required function is unavailable in the local cloud or resources are insufficient, utilizes a “Mediator Cluster” to select the optimal cloud and forward the event to the corresponding function.
- The “Mediator Cluster” monitors resources across all clouds to select the most suitable one and then relays the event.
- The “Trigger service” component within the Mediator Cluster selects the optimal target cluster by using resource monitoring data (e.g., CPU/Memory, network speed) from the “Monitoring component” and operator-defined “Function selection criteria,” and then generates a corresponding event for the chosen cluster.
- Empirical Design and Implementation for Enhanced Job Scheduling in K8s Clusters
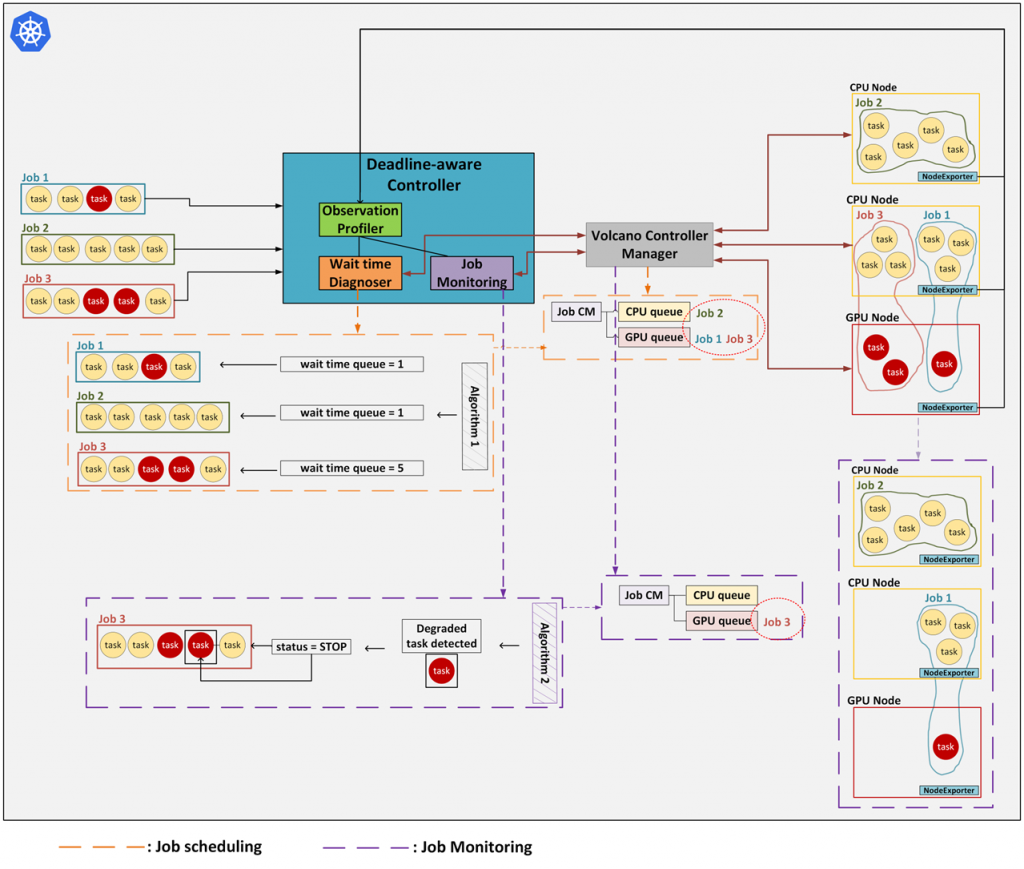
Deadline-aware Job Scheduling: System Architecture and Flowchart
- An empirical design and implementation of a deadline-aware job scheduler for cloud-native environments. The system’s primary goal is to automate the monitoring, provisioning, and maintenance of machine learning (ML) jobs intended for batch scheduling.
- This system analyzes and observes incoming jobs to define appropriate queuing latencies. Guided by its resource management strategy, it then employs various scheduling algorithms to efficiently assign submitted jobs to available resources.
- Furthermore, a sophisticated mechanism has been developed to intervene during the runtime of scheduled jobs. This process aims to achieve optimal performance and ensure user Service Level Agreement (SLA) satisfaction while the job is executing on the resource.